
Chaos Engineering 훈련에 있어 관측 가능성은 중요한 역할을 합니다. 가설에 대한 검증, 정상상태의 동작, 실제 환경의 이벤트에 대한 모의실험, 공격 반경 등이 모두 관측 가능성이 중요한 역할을 하는 실험 단계입니다.
단순히 말하자면, ChaosEngineering – 관측 가능성 = Chaos(혼돈)라고 할 수 있습니다.
여러분의 시스템은 항상 데이터를 생산해 냅니다. 중요한 것은 관측 가능성을 위해 어떻게, 무엇을 사용할 수 있는지 명확히 식별하는 것입니다. 잘 설계된 시스템은 이 데이터를 잘 측정할 수 있습니다. 실험이 이루어지는 동안이 데이터에 즉시 접근할 수 있어야 합니다.
Chaos Engineering의 Observability(관측 가능성)
Chaos Engineering에서 관측 가능한 데이터는 다음과 같은 주요 속성을 가집니다.
Service Health: 서비스가 정상적인 상태인지 나타내는 지표. 통상 마이크로 서비스는 GET Request에 대해 내부적인 확인 과정을 통과하면 HTTP 200으로 응답할 수 있는 URL을 노출합니다. 때론 errors/min 역시 정상상태나 마이크로 서비스의 요청 패턴에 대한 좋은 기준입니다.
Transactions: 마이크로 서비스를 통해 실행되는 비즈니스 트랜잭션의 KPI인 지표. Logins/sec, Checkout/min, Searches/sec 또는 Submits/hour 등의 KPI가 있습니다.
IT Resources:마이크로 서비스에 의한 IT 자원 사용에 대해 통찰력을 제공하는 지표. CPU 사용량, Network IO, Disk read/write 등이 있습니다.
Relevance: 이속성은 어떤 지표가 어떤 대상에 유용한 지 식별합니다. 예를 들어, submit/hour는 운영과 비즈니스에 모두 유용한 반면, credit card type per week는 비즈니스 상품 담당자에게 유용합니다. 관측 가능한 데이터는 특정 대시보드 등을 통해 관련 담당자에게 적절히 전달되어야 합니다.
Telemetry & Instrumentation: 관측가능한 데이터를 수집하여 집계하고, 스트리밍하며, 저장하고 분석하는데 사용되는 도구들입니다. Chaos 실험을이해하고 관측하는데 가장 중요한 요소입니다.
Analytical Insights: 데이터를 분석할 수 있는 플랫폼입니다. 관측가능한 데이터로부터 패턴을 파악하여 상호 연관성, 예측, 회귀 및 학습능력을 제공합니다.
Actions: 단순하거나복잡한 규칙이 적용되면 수행되는 업무들입니다. 마이크로 서비스에 대해 관측 가능한 데이터의 일부로 만들어진 이벤트에 대한 통상적인 응답으로, ‘최대부하가 100 searches/sec를 넘으면 2개의 컨테이너를 추가한다’ 거나 “25개 이상의 Long Running Thread가 감지되고 지난 10분간 CPU 사용량이 90%를 넘으면 JVM을 재 시작한다”등이 예입니다.
실험을 설계할 때 이들 속성들이 어떤 역할을 하는지 이해하는 것이 중요합니다. 예를 들어, 최소한 Health, 트랜잭션, 그리고 IT 자원 사용에 대한 데이터에 접근하지 못한다면 Searches/sec 트랜잭션에 대한 행태를 실험이 영향을 받을 수 있습니다. 운영과 비즈니스 지표를 별도로 보여주는 대시보드가 없다면 마이크로 서비스의 정상상태에 대한 관측 능력이 제한될 것입니다. 적절한 Instrumentation 도구가 없다면, 개발자에게 확인된 오류코드를 수정하는데 필요한 통찰력을 제공하지 못할 것입니다. 분석 기반 통찰력이 없다면 submit/hour의 증가가 어떤 Backend 네트워크의 트래픽에, 얼마나 영향을 주는지 자신 있게 말하지 못할 것입니다
Chaos Engineering에서 이들 7가지 속성은 실험의 성숙도뿐만 아니라 마이크로 서비스에 대한 관측 가능성의 성숙도에도 반영됩니다. SRE 훈련을 팀으로 확장할 때 이 속성들이 사업의 관측 가능성을 정의하기 시작합니다.
Sources of ObservableData (관측 가능한 데이터의 원천)
7가지 속성들을 Chaos 실험을 수행하면서 강조하겠습니다. 관측 가능성에 있어 근간이 되는 원칙 요소들은 Log와 Metrics 그리고 Traces입니다. 이들은 관측이 이루어질 수 있는 데이터를 제공합니다. 서비스 메시에 있어 4가지 주요 신호인 Latency, Traffic, Errors& Saturation은 관측을 위한 기본적인 데이터를 제공합니다. 이 신호는 로그 내에 포함되거나, 애플리케이션이나 인프라 메트릭을 통해 또는 End-to-End Trace에서 찾을 수 있습니다
Traffic 은3개의 모든 원칙 요소에서 관측됩니다. 통상적으로 Traffic에 대한 데이터는 Access Logs, Proxy Logs, APM의 부하 Metrics, Request 이벤트 스트림, 또는 애플리케이션 Trace에 대한 Mining과 같은 웹로그에서 얻을 수 있습니다.
Latency는 Request와 Response 간의 시차를 측정하거나 클라이언트, 서버, 네트워크, 통신 프로토콜 등 다양한 요소의 분포를 분석하여 관측할 수 있습니다. Latency 또한 모든 원칙 요소에서 측정할 수 있습니다. 클라이언트 측이나 서버 측 모니터링 에이젼트를 이용하여 Trace나 웹로그를 통해 측정할 수 있습니다.
Errors는 이름과 달리 매우 중요한 정보의 원천입니다. Configuration 이슈나 애플리케이션 코드 그리고 끊어진 의존성 등에 대한 통찰력을 제공합니다.
Saturation은 자원의 사용량이나 용량에 대한 통찰력을 제공합니다. 자원의 포화도를 관찰하는 것은 평상시 정상상태에서 시스템이 어떻게 동작하는지에 대한 지표를 제공합니다. 인프라의 한계를 이해한다면 미래를 예측할 수 있습니다.
Logging은 데이터를 세부적으로 관찰하는 수단입니다. 특정 시간에 시스템이 어떻게 동작하는지에 따라 다릅니다. 이 데이터는 정교한 입수와 분석 엔진을 통해 의미를 도출하는 데 사용할 필요가 있습니다.
Metrics은 Logging을 보완하지만 시스템의 동작에 따라 스토리지 요구사항이 바뀌지 않기 때문에 저장하기 쉽습니다. 숫자로 이루어져서 쉽게 시각화할 수 있습니다. 비정상 감지, 기계학습, 회귀 기술 등의 분석방법으로 Metrics을 중심으로 의미 있는 데이터를 만들 수 있습니다.
Traces는 데이터가 시스템 내에서 어떻게 흐르는지 깊이 있는 이해를 하게 합니다. 로컬 또는 분산된 애플리케이션 의존성 맵을 이해할 수 있게 하여 의미를 도출하게 합니다.
이제 분산 시스템에서 Chaos 실험을 통해 이들 주요한 원칙 요소 및 신호를 강조하겠습니다.
Chaos 실험의 관측 가능성 실전
· Platform: AWS
· Target: Microservice deployed in ECS Cluster
· Observability: AppDynamics APM
· Chaos Tool: Gremlin
· LoadGenerator: HP Performance Center
· AttackType: Network Packet Loss (EgressTraffic)
· BlastRadius: 100% (3 out of 3 containers)
· Duration: 29 Minutes
애플리케이션 아키텍처
분산 애플리케이션에서는 모든 의존성이 실제 Chaos 주입 지점이 됩니다. 일반적인 의존성에는 Compute 자원, Network 경로, 데이터베이스, 3rd-Party APIs, 그리고 원격 서비스 등이 포함됩니다.
이글에서는 AWS ECS 클러스터에서 운영되는 마이크로 서비스, chaosM에 대해 점진적으로 Network Packet Loss를 증가시키는 시나리오를 수행합니다. 마이크로 서비스는 웹서버 뒷단에서 3개의 Task(ECS)로동작하며 3개의 AWS AZ에 걸쳐 분산되어 있습니다. 기능 측면에서 chaosM은 NAB의 On-Prem App으로부터 Request를 받고 필요한 변환 로직을 적용한 후 결과를 NAB 시스템 외부에 있는 3rd-party 시스템으로 전송합니다. Back-end 타입의 마이크로 서비스입니다.
정상상태에서 관측된 Metrics와 실험 상태에서의 변화는 대상 서비스에 대해 수립한 가설을 검증하는데 도움이 됩니다.
Steady State (정상상태)
정상상태에서 마이크로 서비스를 관측하기 위해 KPI로 불리는 Metrics를 사용합니다 : Traffic, Errors, Latency & Saturation (4개의 주요 신호). 서비스와 실험 가설에 따라 KPI는 바뀔 수 있습니다.
예를 들어, 샘플 마이크로 서비스, chaosM은 비즈니스 통합서비스로 데이터를 변환하고 고도화하도록 설계되었습니다. 고객향 서비스와 다르게 login/sec, submission/minute 등의 비즈니스 Metrics은 없습니다
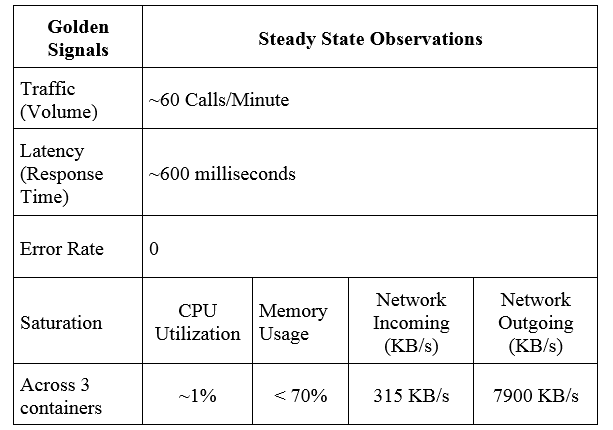
관측 가능한 데이터는 아래 표에 요약되어 있습니다. 정상상태에 대한 온전한 이해는 Chaos Engineering 실험에 있어 필수 요소 중의 하나인 좋은 가설을 생성하는데 도움이 됩니다.
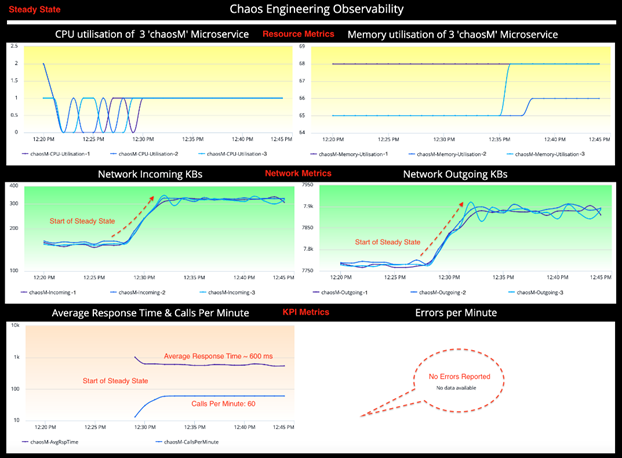
Observations(관측):
다음과 같은 정보들이 정상상태에서 관측되었습니다.
Hypothesis (가설)
서비스 관측 가능성에 기반하여 마이크로 서비스에 대한 몇 가지 가설을 수립합니다:
1. 네트워크의 안정성을 다양한 수준에서 시뮬레이션하기 위해 점진적인 Packet Loss 공격 (40%, 60%, 80%)을 수행했을 때 Error Rate(이 경우 HTTP 500)과 더불어 Latency가 꾸준히 증가할 것이다.
2. Downstream의 단절을 시뮬레이션하는 100% Packet Loss에서, chaosM 마이크로 서비스에서 설정한 5초의 TCP Connect Timeout을 검증할 수 있을 것이다.
Design the Attack (공격 설계)
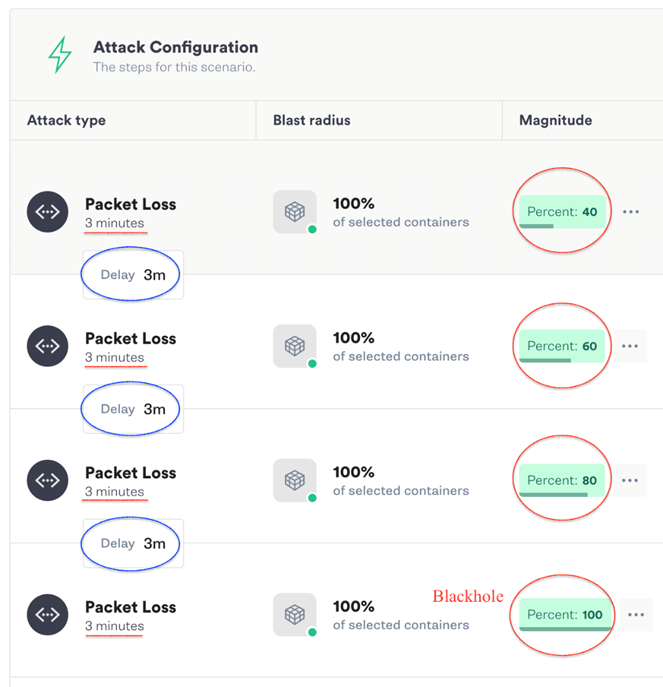
Gremlin의 Failure-as-a-Service (FaaS) 플랫폼을 4개의 점진적인 NetworkPacket Loss 공격(i.e. 40%, 60%, 80% & 100% packet loss 스크린숏 참조)을 설계하고 수행하기 위해 사용하였습니다. 각 공격은 3분간 지속되며, 각 공격 간 3분의 지연을 두어 각 공격 사이에는 정상상태로 돌아와 관측을 구분할 수 있도록 하였습니다.
따라서, 전체 공격시간은 (3 분 x 4회 공격) + (3분 지연 x 3) = (12+ 9) = 21분입니다.
본 관측에서 실험 시작 전과 후에 4분을 추가하여 전체 관측시간은 29분입니다.
Experiment State (실험 상태)
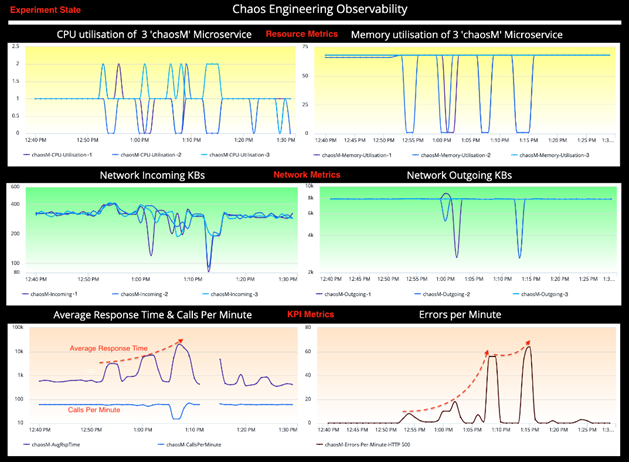
실험 상태의 대시보드는 동일한 KPI를 보여주어 chaosM 마이크로 서비스가 공격 중에 어떻게 동작하는지 이해하게 해 줍니다. 앞서 세운 가설을 검증하기 위해 정상상태와 실험 상태 간의 비교분석을 수행합니다. KPI를 살펴보면 Chaos 이면에 대해 많은 것을 알 수 있습니다.
Observations(관측):
다음과 같은 정보들이 실험(Chaos) 상태에서 ChaosEngineering 대시보드로부터 관측되었습니다.
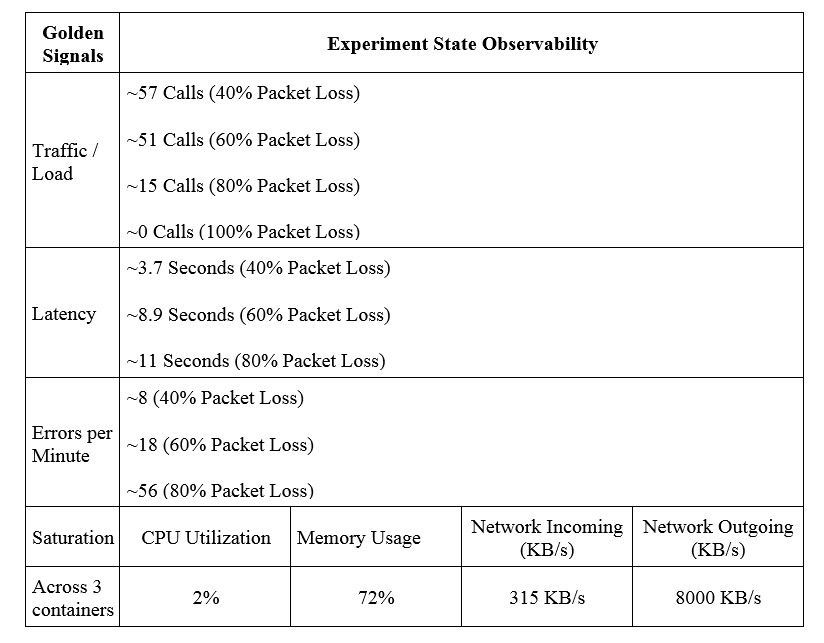
Comparative Analysis (비교 분석)
비교분석을 통해 얻은 기술 통찰력은 특정 실패(Failure)의 분류에 따라 객관적으로 잠재적인 약점(설계, 코딩 및 Configuration 상에서)을 식별하게 해 주었습니다. 객관적으로 판단했을 때 Chaos Engineering은 완벽하게 장애가 없는 서비스를 만들어주지는 않습니다. 그와 반대로, 여러 측면 중에서 Known-unknowns를 밝혀 서비스의 견고함을 검증하도록 해줍니다.
Latency & Traffic
쉽게 비교하기 위하여 정상상태와 실험 상태의 SLI를 나란히 비교하였습니다. 가설에 대한 검증은 중요하지만 실험의 최종 목표는 아닙니다. 마이크로 서비스의 동작방식과 관련된 Metrics를 이해하기 위해서는 많은 부분들이 추가적으로 설명되어져야 합니다.

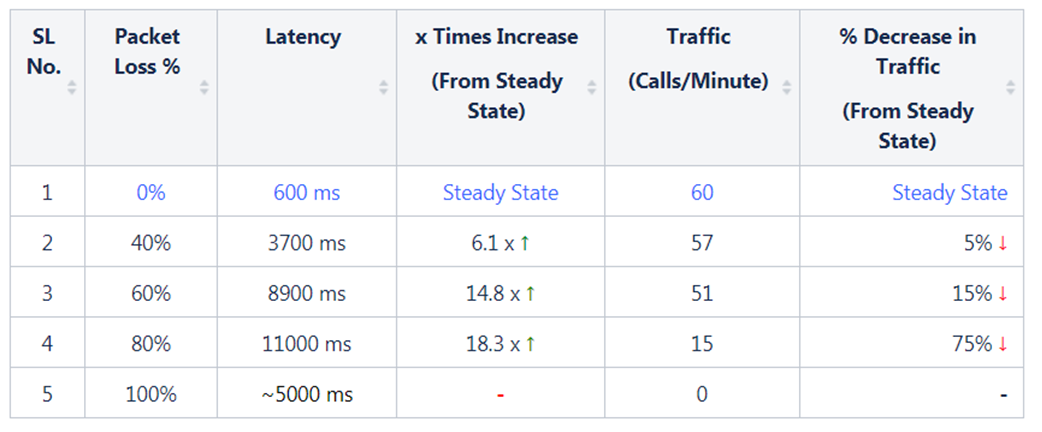
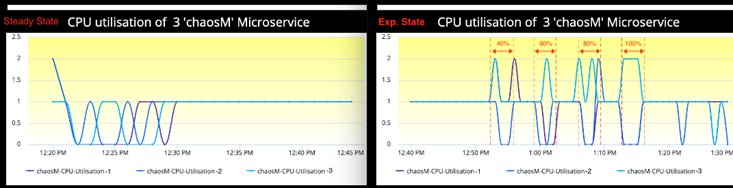
(1) chaosM 마이크로서비스의 Latency가정 상상태에서는 ~600ms인 반면, 3700ms (40% Packet Loss), 8900 ms (60% Packet Loss) 그리고 최대 11000 ms (80% Packet Loss)으로 실험 상태에서 점진적으로 Latency가 증가하였습니다. Latency 증가는 Packet Loss 공격의 정도에 비례함으로써 첫 번째 가설은 검증되었습니다.
(2) 100% packet loss (블랙홀)에서는 Downstream이 완전히 단절되었고 Configuration에 따라 5초 지연시간 이후 TCP Connection Timeout으로 이어졌습니다. 이는 두 번째 가설을 검증합니다.
Note: 위 그림에서 끊어진 Metric 그래프 구간이 블랙홀을 나타냅니다.
Errors
정상상태에서 chaosM 서비스에서 보고된 Error는 없습니다.
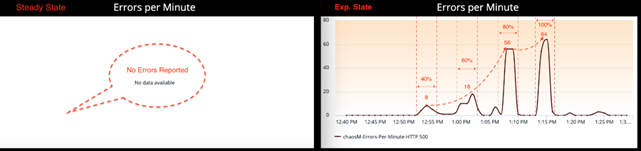
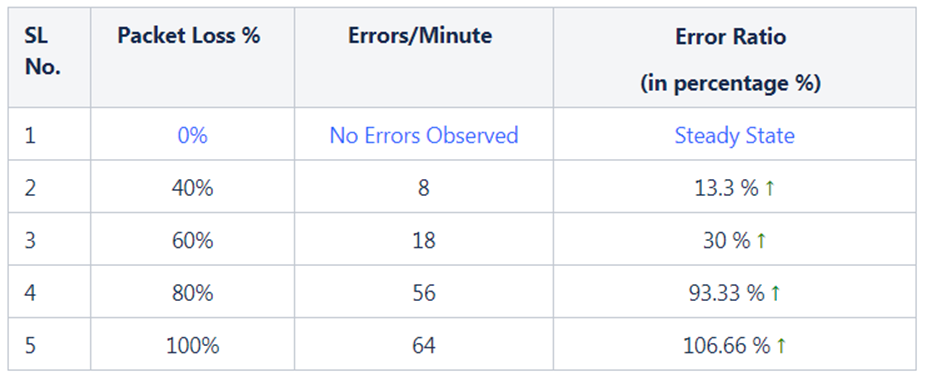
Packet Loss 공격에 대해 비례적으로 증가한 Latency와 다르게 Errors/Min Metric은 정상상태 0 Error에서 40% Packet Loss에서 8 Errors, 60%에서 18 Errors, 80%에서 56 Errors로 기하급수적으로 증가하였습니다. (위 스크린숏 참조) 직관적으로 들리지 않을 수 있지만, 이 수치는 Chaos 공격과 마이크로 서비스에 미치는 영향은 항상 선형적인 관계를 보이는 것은 아닙니다.
Saturation: CPU, Memory (포화도: CPU, Memory)
정상상태에서 CPU 사용량은 모든 컨테이너에서 1%였습니다. 실험 상태에서 동일 Metric이 Packet Loss의 정도와 무관하게 2%로 올라갔습니다.
동일한 관측이 Memory 사용량에서도 마찬가지였습니다. 실험으로 정상상태 대비 Memory 사용량에 미치는 영향은 거의 없었습니다.
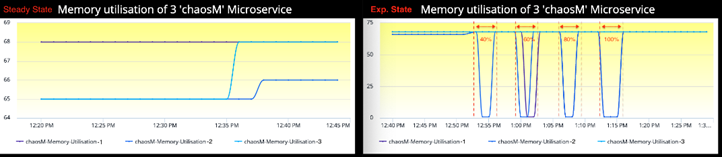
CPU와 Memory 관측에서 모두에서 실험 상태를 자세히 보면, 점선으로 표시된 공격 기간 동안 하나 이상의 컨테이너에서 눈에 띄는 변화가 있습니다. 이 형태는 Gremlin Agent가 동작하는 방식과 AppDynamics Agent가 컨테이너 환경에서 Metric을 보고하는 방식에 기인합니다.
짧게 설명하 자면, Docker에서 공격을 수행하면 Gremlin은 동일한 Replica를 동일한 Control Group Namespace에 올립니다. 두 개의 컨테이너가 동일한 ControlGroup Namespace에서 동작하기 때문에 동일한 ProcessID, IPC 및 Network 리소스를 공유하게 됩니다. Gremlin은 원본은 그대로 두고 Replica 컨테이너에 공격을 수행합니다.
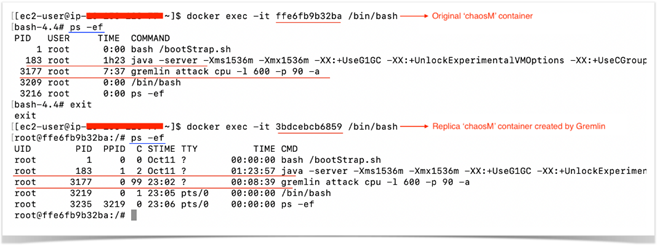
Replica 컨테이너는 공격이 이루어지고 있는 동안만 존재하며 이후 Gremlin Agent는 원본을 남기고 삭제합니다. Process 공간 또한 같기 때문에, AppDynamics Agent는 원본 컨테이너 대신 Replica 컨테이너로부터 Metric을 보고할 때도 있습니다. 둘 간을 구분할 수 있는 방법은 없으며 이러한 형태는 CPU나 Memory 사용량 그래프에서 비정상적으로 관측된 부분을 설명합니다.
Saturation: Network (포화도: Network)
그래프상에 강조된 바와 같이, 네트워크 볼륨 상의 증가는 chaosM 마이크로 서비스의 정상상태입니다. 이 Metric 그래프는 각 Availability Zone에 배포된 3개의 컨테이너에 걸쳐 분산된 incoming/outgoing 트래픽을 보여줍니다.
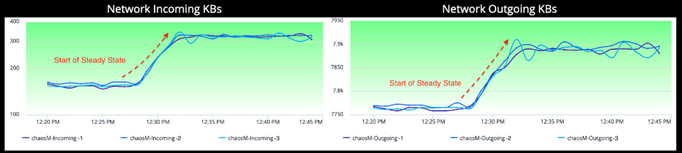
실험 상태의 Network Incoming Metric은 많은 파동을 보여주고 있습니다. Metric 그래프에서 주변의 노이즈를 무시하고 본다면, 특히 60%, 80% Packet Loss 공격 시에 Incoming Traffic이 실험이 진행됨에 따라 떨어지는 추세를 볼 수 있습니다.
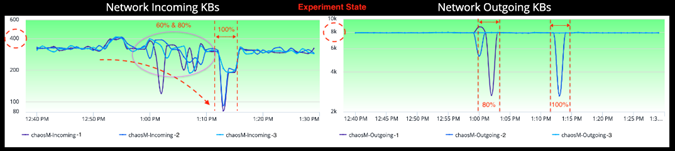
Observability for a Developer (개발자를 위한 관측 가능성)
지금까지 관심은 주로 마이크로 서비스의 전반적인 Health를 결정하는 KPIs(Latency, Traffic, Errors & Saturation)에 초점이 맞춰져 있었습니다. 서비스 성능이 떨어지거나 서비스에 장애가 생긴다면 하나 이상의 KPI에 반영이 될 것입니다. 하지만 Metrics은 이슈에 대한 징조를 보여주지만 근본 원인을 꼭 보여주지는 않습니다. 따라서 다른 각도에서 데이터를 살펴볼 필요가 있습니다.
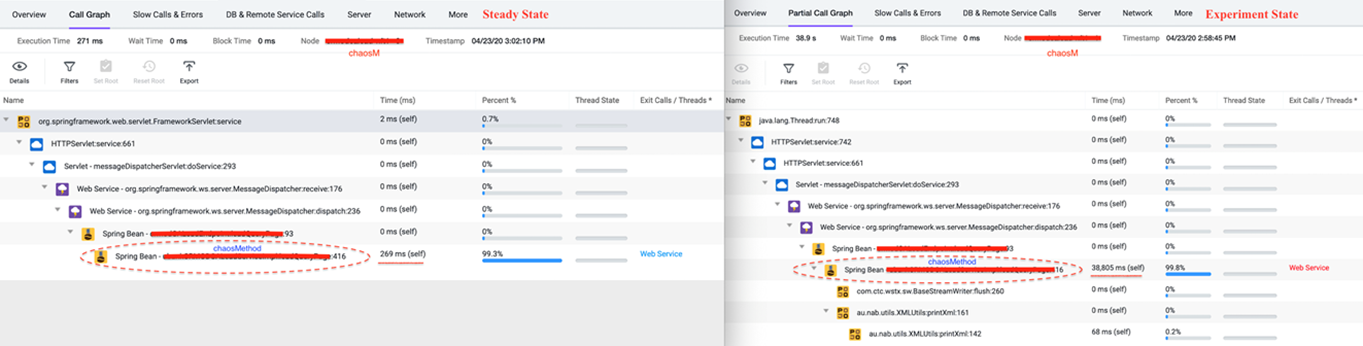
APM 모니터링 솔루션은 마이크로 서비스에 대해 개발자 관점에서 코드 수준의 통찰력을 제공하며 취약한 코드 세그먼트를 노출해 주기도 합니다.
예를 들어, 위 그림은 chaosM 마이크로 서비스의 정상상태와 실험 상태의 Waterfall 모델을 보여줍니다. 각 Waterfall 모델의 단계는 실행시간에 따른 코드 세그먼트를 나타냅니다. 코드 세그먼트 Spring Bean (chaosMethod:416) 은 실험 38,805 ms 즉, 38.8초가 소요되었습니다. 반면 동일한 코드 세그먼트가 269 ms 소요되었습니다. 38.8초는 코드 세그먼트 Spring Bean (chaosMethod:416)에 대한 PacketLoss 공격의 영향을 나타냅니다
코드 수준의 통찰력은 모니터링 (AppDynamics)에서 나온 시스템 수준의 가시성과 함께 Chaos Engineering 실험을 통해 시뮬레이션하는 다양한 부하 조건 및 장애 시나리오에서 마이크로 서비스의 내부 동작을 이해하는 데 도움이 됩니다. 서비스의 안정성에 있어 추측이나 희망이란 없습니다. Chaos 실험을 통해 얻은 데이터는 SRE와 서비스 담당자들이 객관적으로 실제 환경의 이벤트를 기반으로 서비스의 안정성을 객관적으로 평가하는 능력을 키워줄 것입니다
To conclude (마치며)
실제로 실험이 이루어지는 것을 보았으며 관측 가능한 데이터도 보게 되었다. 중요 신호(Golden Signals)로 알려진 관측가능한 데이터셋에서 중요한 데이터에 대한 통찰력을 제시하였습니다.
관측 가능성은 데이터를 이해했을 때 가치가 있습니다. 내부를 들여다보고 “왜”라는 질문에 답할 수 있을 때 운영자와 개발자 모두를 위한 답을 찾을 수 있습니다. 스스로 가설을 세우고 실험을 진행했을 때 Known-Unknowns과 Unknown-Unknown을 발견할 수 있습니다. 전통적인 안정성 테스트로 어느 정도 갈 수 있겠지만 Chaos Engineering 수행하고 관측 가능한 데이터를 면밀히 분석해야만 더 멀리 갈 수 있습니다.
이것이 관측 가능성의 근간이며 어떤 데이터를 찾을지, 실험을 통해 어떤 데이터를 발견하고 서비스 안정성에 대해 탄탄한 이해를 갖추는 것입니다. 이것은 단순 모니터링에서 한 단계 더 나아가는 것입니다. Chaos Engineering은 데이터가 존재하는 이유를 이해하지 못한다면 도움이 되지 않습니다.
100% 안정성은 없습니다. 하지만 Chaos 실험과 실험을 통한 관측 가능성은 왜 그런지 그리고 서비스에 대한 고객의 확신을 올려줍니다. 대응만 할 것이 아니고 고객보다 앞서서 관찰하고 잘 대응하여야 합니다.




