
Uptime Institute에서 발표한 최신 연례 설문조사인 2022년 데이터 센터의 가동 중지 시간에 대한 보고서를 보면 데이터 센터의 가동 중지 시간의 빈도는 크게 변화하지 않았으나 가동 중단 시간이 점점 더 길어지고 그에 따른 비용도 증가하고 있다는 것을 확인할 수 있습니다. 데이터 센터 중단의 추세와 관련한 자세한 내용 살펴보겠습니다.
(1) 데이터 센터 가동 중지의 시간이 장기화되는 것이 일반화되고 있습니다. 지난 5년 동안 데이터 센터의 중단과 완전한 복구에 소요되는 시간은 계속해서 크게 늘어났으며 2021년에는 중단 사태가 발생하고 복구하기까지 24시간 이상 소요된 비율이 약 30%에 달했습니다.
(2) 데이터 센터가 중단되면서 발생한 손실도 크게 증가했습니다. 조사 결과 60% 이상이 총 손실액이 최소 $100,000 이상인 것으로 집계되었고 이는 2019년의 39%의 수치에서 대폭 증가한 수치입니다.
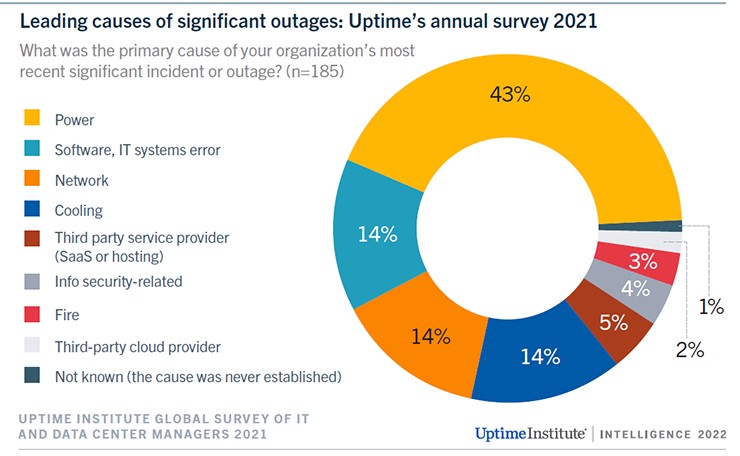
(3) 네트워킹 문제는 심각도와 관계없이 지난 3년 동안 모든 IT 서비스 다운타임 사고의 가장 큰 원인이 되어 왔습니다. 이는 클라우드 기술, 소프트웨어 정의 아키텍처 및 하이브리드 분산 아키텍처의 사용 증가로 인한 복잡성 때문이라고 추측합니다.
중요한 것은 지난 2년 동안 더 긴 다운타임이 발생하는 횟수가 증가했다는 것입니다. 그중 일부는 지난 10월 발생한 Meta의 대규모 다운타임입니다. 페이스북은 구성 오류로 인해 주요 네트워크 백본에 대한 연결이 끊어져 인터넷에서 데이터 센터 연결을 해제했다고 밝혔습니다. 해당 사건으로 인해 Facebook, Instagram 및 WhatsApp이 최소 5시간 동안 운영 중단되었습니다.
또 다른 예로는 2021년 10월 발생한 Roblox의 73시간 다운타임 사태입니다. 온라인 게임 및 메타버스 플랫폼 Roblox는 73시간 동안 5천만 명의 일일 사용자를 오프라인 상태로 만들었고 약 2,500만 달러의 손실이 발생했습니다. 그 외에 네트워크 문제, 전력 및 장비 문제로 큰 사건들이 여럿 발생했었습니다.
디지털 서비스가 거의 모든 비즈니스의 중심이 된 현재, 다운 타임으로 인한 손실은 그동안 데이터 센터의 유지 및 관리의 가치를 강조해왔지만 이제는 데이터 인프라에 대한 의존도가 높아짐을 반영하기도 합니다. 다운타임 손실 비용을 막기 위해서는 데이터 재난 상황을 방지하고 상황 발생 시 이를 효과적으로 복구할 수 있는 방안이 마련되어야 합니다. 대부분 다운 타임을 줄이기 위해서 1) 코드를 철저히 테스트하고 2) 소프트웨어 엔지니어와 SRE가 제 역할에 충실하기를 바랍니다. 하지만 이러한 방법으로는 가동 중지 시간을 최소화할 수 없습니다. 최신 소프트웨어 아키텍처는 그 어느 때보다도 분산되어 있고, 이 덕분에 프로그램이 더 안정적으로 보일 수 있으나 사실은 굉장히 복잡해 또 다른 문제들을 안겨주곤 합니다.
다운 타임 손실 비용을 예방하기 위해 성숙된 조직은 code test coverage와 DevOps를 넘어서서 Chaos Engineering을 연습합니다. 그리고 이를 통해 다운타임이 발생하기 전에 아키텍처의 취약점을 찾아냅니다. 인위적인 장애를 발생시키면서 취약점을 선제적으로 파악할 수 있는 솔루션인 Gremlin과 장애 발생 상황에서 즉시 대처하며 데이터 손실 없이 서비스 중단 시간을 최소화하는 솔루션 Dbvisit에 대해 알아보세요
Gremlin 더 알아보기 : https://www.osckorea.com/solution/gremlin
Dbvisit 더 알아보기 : https://www.osckorea.com/solution/dbvisit
참고
https://datacenterfrontier.com/metaverse-platform-roblox-adds-data-center-to-address-73-hour-outage/




